Hacker News Sidebar: An Extension for Google Chrome
tldr: I’ve fixed up the Hacker News Sidebar Chrome extension. It shows comment threads from HN in a handy tab next to any other pages that you visit. Browse the source code on GitHub, and install the extension from the Chrome Store.
Like many other web developers, I use Google Chrome as my primary web browser because it is incredibly fast, the UI gets out of the way, and the web development tools are superlative. That might change some day—Firefox is making a comeback with regard to all of these things, and I like using it as well, just not quite as much to make me switch back yet.
One surprisingly nice thing about Chrome is that it is really easy to develop extensions, particularly if you are a web developer. Generally all that’s required are a few JavaScript files and optionally some HTML and CSS and you could do anything from bookmark syncing, page syncing across devices, or elimination of those pesky tracking scripts. Admittedly there are limitations: you can only modify the browser UI in a few specific ways, like adding buttons or icons next to the Omnibox that pop out content, or items to the context menu.
Chrome extensions function much like an offline HTML5 app, running in the background as a hidden tab. Besides all the typical features of the DOM, like the XHR object for asynchronously communicating with webservers, they can access special Javascript APIs (under the chrome global object) for opening and manipulating tabs, history, windows, and bookmarks. They can also selectively insert Javascript into webpages, like the Greasemonkey scripts or Userscripts that are popular for enhancing the functionality of certain websites. To securely communicate between code running in the user’s browser tabs and your extension’s hidden background tab, you use a messaging API. All the special permissions your extension needs must be specified in a manifest.json file.
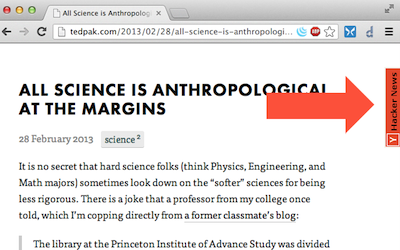
As you may have guessed by the links at the end of each post on this blog, I read HN quite a bit—enough so that I’d rather just direct any discussion to that forum, rather than try to police my own comments database. Meta-discussions on link-aggregating websites (e.g. HN, reddit) are often more interesting than the original content. Once upon a time I used this Chrome extension to reveal these HN threads automatically: it would pop out a side tab on any page that had been posted to HN. Whenever the orange tab happily emerged, a quick scan of the sidebar would show what HN thought and how many upvotes it had, sometimes significantly changing my impression of the original page.
Unfortunately, that extension has fallen into disrepair. HN has switched to HTTPS and now disallows framing of their site via the X-Frame-Options: DENY header 1, causing the tab to be blank. Additionally, the Chrome extension packaging scheme has changed to tighten security policies, so barring some serious updates, this extension will stop working in September 2013. In order to get this extension running again, I had to rewrite much of it. Let’s break down the source code.
All Chrome extensions begin with a manifest.json file. The first half of this file says that I need the xhr_handler.js script to run in my background tab, and I need to insert hn.css, jquery.js, and script.js into all pages (as specified by matches). Note that through some scoping magic that Chrome does, these inserted scripts will not interfere with any global variables or functions created by their host pages, but they will still be able to affect the DOM. Finally, there is some metadata for the Chrome Store in the second half, along with permissions, which enumerates the domains that I want my background script to be able to access.
{
"manifest_version": 2,
"background": {"scripts": ["xhr_handler.js"]},
"content_scripts": [ {
"css": [ "hn.css" ],
"js": [ "jquery.js", "script.js" ],
"matches": [ "http://*/*", "https://*/*" ]
} ],
"icons": { "48": "icon-48.png",
"128": "icon-128.png" },
"description": "Hacker News integration for Chrome",
"name": "Hacker News Sidebar",
"permissions": [ "http://api.thriftdb.com/api.hnsearch.com/items/*", "https://news.ycombinator.com/*" ],
"version": "1.0.8"
}Let’s look at the script.js file next, which will be inserted into every page I visit. For the most part, this looks like a run of the mill jQuery script. The first atypical tidbit is this:
var port = chrome.extension.connect({}),
callbacks = [];
// ...[snip]...
port.onMessage.addListener(function(msg) {
callbacks[msg.id](msg.text);
delete callbacks[msg.id];
});
function doXHR(params, callback) {
params.id = callbacks.push(callback) - 1;
port.postMessage(params);
}This appears to be a wrapper for performing XHR (also called AJAX requests), but why all the bother when I would typically just use $.ajax? Well, despite their special scope, content scripts still execute with all the cross domain restrictions that the host page has; they can’t perform AJAX requests outside the host, port, and protocol the host page was served rom. That’s a problem because we need to pull outside content from both the HNSearch API and HN itself. So, to work around this, the code packages the parameters for the XHR into a message that is sent via the Message Passing API under the special chrome global object to the background script, xhr_handler.js, where it can executed with the correct permissions.
What happens there? Let’s see:
function xhrCall(url, port, id) {
var xhr = new XMLHttpRequest();
xhr.open("GET", url, true);
xhr.onreadystatechange = function() {
if (xhr.readyState == 4) {
port.postMessage({id: id, text: xhr.responseText});
}
};
xhr.send();
}
chrome.extension.onConnect.addListener(function(port){
port.onMessage.addListener(function(request) {
xhrCall(request.url, port, request.id);
});
});Pretty much all it does is actually perform the XHR request and send the responseText (the raw text content of the response) right back. Note the use on both ends of the port.postMessage method to send data and the addListener methods to create event handlers that receive data. This is very reminiscent of the HTML5 Web Workers API.
So now that we can perform XHR to the necessary outside sites, back in script.js, we query the HNSearch API filtering by the URL of the current page:
var exclude = /\.(xml|txt|jpg|png|avi|mp3|pdf|mpg)$/;
// ...[snip]...
var curPath = window.location.href;
if (exclude.test(curPath)) { return; }
var queryURL = "https://api.thriftdb.com/api.hnsearch.com/items/_search?filter[fields][url][]=" \
+ encodeURIComponent(curPath);
doXHR({'action': 'get', 'url': queryURL}, function(response) {
// JSON.parse will not evaluate any malicious JavaScript embedded into JSON
var data = JSON.parse(response);
// No results, maybe it's too new
if (data.results.length < 1) {
doXHR({'action':'get','url': HN_BASE + "newest"}, function(response) {
searchNewestHN(response);
});
return;
}
// If there is a result, create the orange tab and panel
var foundItem = data.results[0].item;
createPanel(HN_BASE + 'item?id=' + foundItem.id);
});and if we find results, we kick off creation of the orange tab with createPanel; if not, we give the newest HN stories a try with searchNewestHN, in case this is a story that just made it to the front page. searchNewestHN works by parsing the HTML of the front page and finding any anchors that link to this page.
function searchNewestHN(html) {
var titleAnchor = $('a[href=\'' + window.location.href.replace(/'/g, "\\'") + '\']', html),
linkAnchor = titleAnchor.parent().parent().next().find('a').get(1);
if (linkAnchor) {
createPanel(HN_BASE + $(linkAnchor).attr('href'));
}
}If it does find it, it too calls createPanel. The createPanel function is pretty dry with a lot of dry DOM construction, but the fun part is when we actually need to put the HN comment thread into the DOM:
function createPanel(HNurl) {
// ...[snip]...
var HNembed = $("<div />").attr({'id' : 'HNembed'});
var HNsite = $("<iframe />").attr({'id' : 'HNsite', 'src' : 'about: blank'});
// ...[snip]...
HNembed.append(HNsite);
HNembed.hide();
$('body').append(HNtab);
$('body').append(HNembed);
doXHR({'action': 'get', 'url': HNurl}, function(response) {
var doc = HNsite.get(0).contentDocument;
response = response.replace(/<head>/, '<head><base target="_blank" href="'+HN_BASE+'"/>');
doc.open();
doc.write(response);
doc.close();
});
}This is not your typical use of an <iframe>: instead of setting the src attribute to the comment thread URL, which we can’t do because HN forbids framing, we have to leave it as about:blank, fetch the contents of the comment thread page via XHR, and then write to the <iframe>’s document object extracted with the contentDocument property. We can write the same HTML that HN serves, with one modification: by adding a <base> element to the <head> of this document, we can ensure that all the links within are followed relative to HN, and not the URL of the host site. The .open() and .write() calls here are indeed those yucky methods you have been taught to never use since DOM scripting became practical, and in general you really shouldn’t, but here it is fair game because the document we are writing to is completely empty.
So, after all of that lovely bit-pushing, we get a collapsible sidebar with an HN comment thread in it! To try it out yourself, install the extension from the Chrome Store, or clone the source code and load the directory into Chrome as an unpacked extension.
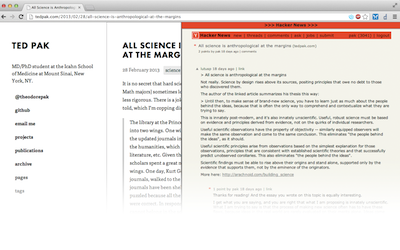
One note on a privacy weakness of this extension, which you may have noticed if you were following the code above: the extension sends all the URLs that you visit to https://api.thriftdb.com/. Obviously, that isn’t going to be acceptable for some users, but there’s no way to look up Hacker News threads for all the URLs you visit without sending those URLs somewhere. The Hacker News’d extension, which does something similar but doesn’t add the comment thread to the browser window, makes a strange attempt to mitigate privacy concerns by MD5ing URLs, but then it requires a special server-side component that is constantly scraping the front page and shoving the MD5s into a MongoDB on Heroku, and besides that MongoDB being necessarily more incomplete than the official API, it doesn’t really solve the privacy problem anyway. So, if you want to use this on your primary browser you basically have to trust the ThriftDB folks with your browsing history (hey, at least it’s being sent over SSL).
-
Presumably, HN uses the relatively new X-Frame-Options header to prevent people from embedding HN comment threads directly into their own site, either because they don’t want them surrounded by other people’s content or because they want to block clickjacking schemes for tricking users into upvoting items. Unfortunately this also precludes the simplest method of accomplishing what the extension used to do—loading the comment thread into an
<iframe>by setting itssrcattribute. I suppose I could have also tried to get around this restriction by modifying HTTP headers as they are received, but the way I did it seemed easier. ↩
Discuss this post on HN.